Replication
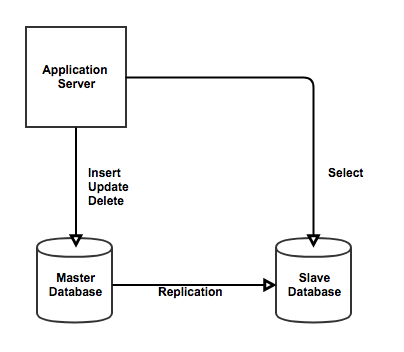
두 개 이상의 DBMS 시스템을 Master/Slave로 나눠서 동일한 데이터를 저장하는 방식이다.
Master에는 데이터의 수정사항을 반영하고 Slave에 실제 데이터를 복사한다.
로그기반 복제(binary log)
- Statement Based: SQL문장을 복사하여 진행
- issue: SQL에 따라 결과가 달라지는 경우(Timestamp, UUID, …)
- Row Based: SQL에 따라 변경된 Row 라인만 기록하는 방식
- issue: 데이터가 많이 변경된 경우 데이터 커질 수 밖에 없다.
- Mixed: 기본적으로 Statement Based로 진행하면서 필요에 따라 Row Based를 사용한다.
하나의 서버와 하나의 데이터베이스로 운영하고 있다고 가정하자.
사용자는 점점 많아지고 데이터베이스는 많은 query를 처리하기 힘든 상황에 처하게 된다.
query의 대부분을 차지하는 select(read)를 어느 정도 해결하기 위해 replication 방법을 사용하게 되었다.
Replication 장점
-
부하분산
쓰기/변경은 Master에서 작업하지만 읽기 작업은 Master/Slave 둘다 가능하기 때문에
Slave에서 읽기만 하는 방식으로 각각의 부하를 분산할 수 있다. -
고가용성 / 장애복구
Master에서 장애 발생 시 Slave를 통해 장애 복구 시간을 줄일 수 있다. -
로그
Master 영향없이 로그를 분석할 수 있다.
Replication 단점
-
Master-Slave pair 관리
서버가 많아질 경우 Master와 Slave 짝을 맞춰서 관리해야 한다. -
실패 상황에서의 복구
Master에서 실패 시 Master와 Slave의 교체
횩은 Slave의 데이터를 Master로 복사하는 작업을 수동으로 진행해야 한다.
Slave에서 실패했을 때도 마찬가지다.
Spring Boot 프로젝트
ReplicationRoutingDataSource
여거 개의 데이터소스를 하나로 묶어 자동으로 분기처리한다.
public class ReplicationRoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
String dataSourceType =
TransactionSynchronizationManager.isCurrentTransactionReadOnly() ? "read" : "write";
return dataSourceType;
}
}
그러나 이 설정 만으로는 원하는대로 Master/Slave에 분기처리되어 작동하지 않는다.
TransactionSynchronizationManager가 @Transactional로 선언된 현재 스레드의 트랜잭션 상태를 읽어오는게 가능하더라도 동기화(synchronation)시점과 Connection 객체를 가져오는 시점에 문제가 있기 때문이다.
Spring은 @Transactional 어노테이션을 만나면 다음 순서로 일한다.
TransactionManager 선별
→ DataSource에서 Connection 획득
→ Transaction 동기화(Synchronization)
트랜잭션 동기화를 마친 뒤에 커넥션을 획득해야 내가 원하는대로 동작하는데
Spring은 커넥션을 먼저 획득하기 때문에 Master에서만 작업한다.
LazyConnectionDataSoruceProxy
커넥션을 획득하는 시점 문제를 해결하기 위해서, 즉 트랜잭션 동기화를 마친 후에 커넥션을 획득하기 위해
ReplicationRoutingDataSource를 LazyConnectionDataSoruceProxy로 감싸준다.
@Bean
public DataSource routingDataSource(DataSource writeDataSource, DataSource readDataSource) {
ReplicationRoutingDataSource routingDataSource = new ReplicationRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<Object, Object>();
dataSourceMap.put("write", writeDataSource);
dataSourceMap.put("read", readDataSource);
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(writeDataSource);
return routingDataSource;
}
@Bean
public DataSource dataSource(DataSource routingDataSource) {
return new LazyConnectionDataSourceProxy(routingDataSource);
}
실질적인 쿼리 실행 여부와 상관없이 트랜잭션이 걸리면 무조건 Connection 객체를 확보하는 Spring의 문제점을 해결하여 트랜잭션 시작 시 Connection Proxy 객체를 리턴하고 실제 쿼리가 발생할 때 dataSource에서 getConnection()을 호출하는 역할을 한다.
작동 순서
TransactionManager 선별
→ LazyConnectionDataSourceProxy에서 Connection Proxy 객체 획득
→ Transaction 동기화(Synchronization)
→ 실제 쿼리 호출시 ReplicationRoutingDataSource.getConnection()/determineCurrentLookupKey() 호출
TransactionManager나 영속 계층 프레임워크는 dataSource만 바라보고 writeDataSource, readDatasource, routingDataSource는 설정에만 존재할 뿐 영속 계층 프레임워크는 이 존재를 몰라야 한다.
주의
절대로 한번 읽어들인 커넥션을 readOnly 설정을 바꿔서 재활용하면 안된다.
일단 실제 커넥션을 획득하면 중간에 속성을 바꿔도 다른 커넥션을 새로 맺지 않는다.
Spring은 propagation이 REQUIRES_NEW 일 경우 비록 동일 DataSource에서 커넥션을 가져오더라도 새로운 커넥션을 맺기 때문에 아무 문제 없이 작동한다.
하지만 propagation이 REQUIRED 일 경우에는 새로운 트랜잭션을 생성하지도 않고 새로운 설정을 적용하지도 않으므로 주의해야 한다.